In this session, we are going to discuss the MapReduce process flow in more details. We are going to see the flow process that includes Shuffle, understand what Shuffle step works and we will see an optional step that can be added to our job is called Combine, understand the benefits that a combine step adds to our job. Finally we will go through an example where we will write the Combine code. So in this section, we are going to learn about these concepts:
- MapReduce Process Flow
- Shuffle
- Sort
- Combine
- Example with combiner same as reducer
- Example with combiner different to reducer
- Exercise to Complete
MapReduce Process Flow:
So far we have seen some simple examples of MapReduce. To write complex MapReduce functionalities, let’s explore the process flow of a MapReduce job. In the previous examples, we have seen so far
public void map(Text key, Text value, Context context){
//map logic here
context.write(key,value);
}
The map() method takes input parameter of a key and a value and within the map() method we write a key and a value to context. We can write these key, value pairs to the context object many numbers of times within the map() methods. Hadoop requires input data to map() in the form of a MAP i.e., a list of keys and values. We can either provide a MAP of data directly, for example, we could have a file of comma/tab separated keys and values, or we can simply provide values in a file, that is what we have done so far. If we only provide values, Hadoop would automatically take line offset from starting of the file as the key. The key which Hadoop takes automatically depends on the Input Format we will use in the job configuration and for the TextInputFromat it is the Line Offset from the starting of the file. As we have discussed so far key wasn’t important for us and we didn’t write any code on the map() to use the key we were dealing with the values only. This is very common to a Hadoop job we have to have a key to our input data but we can often ignore it and if we don’t supply any key, Hadoop will generate one for us. We will see how to provide the key in the input data later in the course.
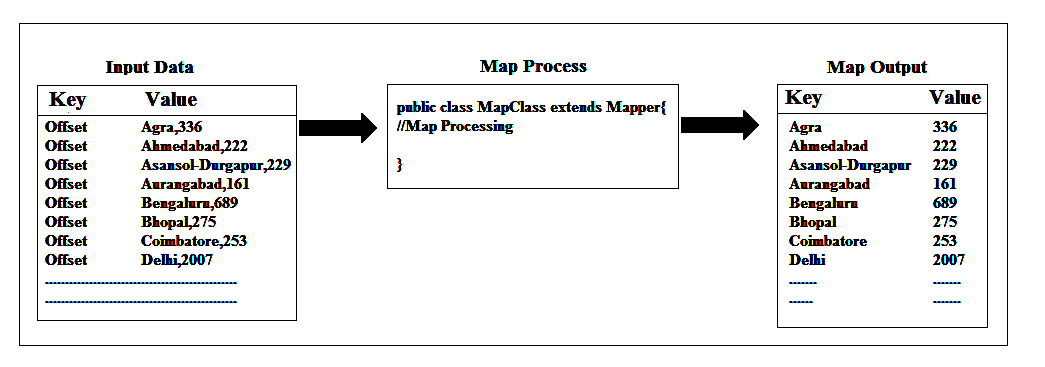
The map() method would call once for each data item in our source data. Suppose if we have a file with 100 lines of data, the map() method will be called 100 times. The output of map() method would be a new MAP of keys and values.
The reduce() method format is slightly different, the method parameters are a key and an Iterable list of values not a single value. So the map() method called once for each data item the reduce() method is called once for each key.
public reduce(Text key, Iterable<Text>values, Context context){
//reduce logic here
context.write(key,value);
}
Before the reduce() method runs, Hadoop groups together all the data items with the same key to a single list of values, so that reduce() method can call once for each key, and we have all of the values for a particular key available to us with our reduce() method.
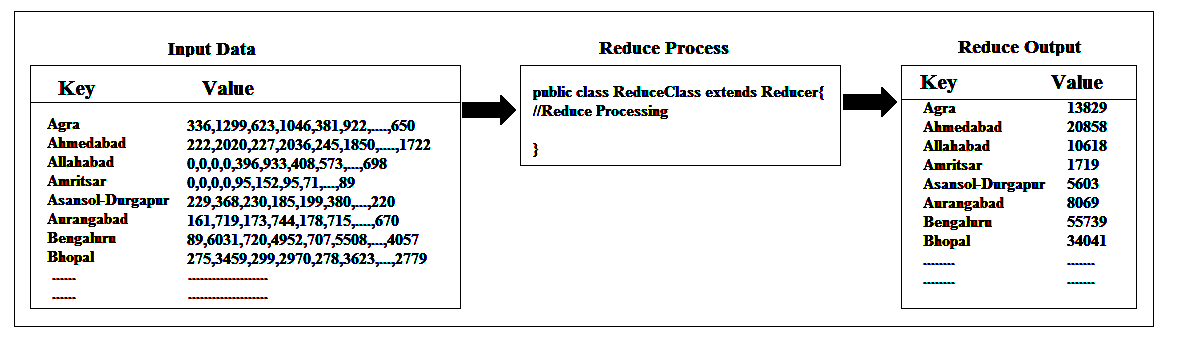
That’s why we have written our reduce() method to sum up all the values in the examples so far and it worked because when we called the reduce() method we had all the values available with us.
Shuffle:
Shuffle is an extra step that takes place after the map process completes and before the reduce process is started. This step groups together the map results by keys. Although we don’t have to write any code for Shuffle step, it happens automatically, it has the very important role in the MapReduce process. It will be easy to understand if you think about a cluster with lots of nodes
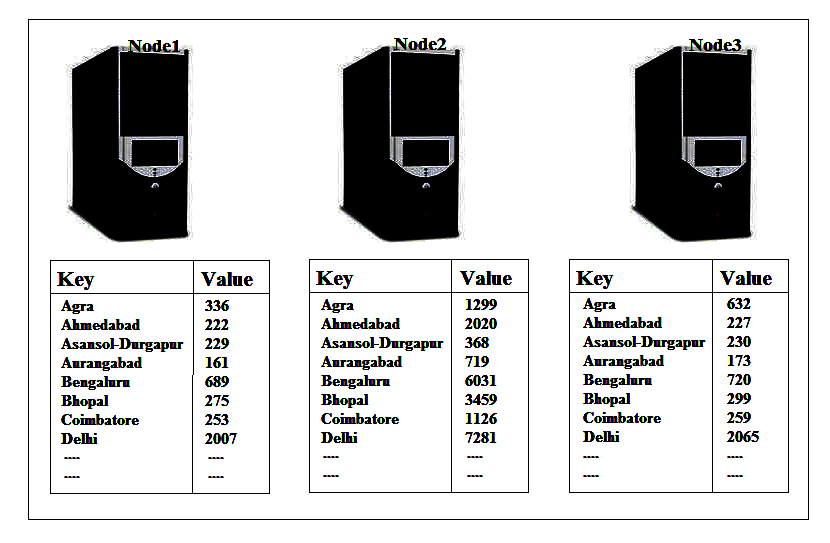
As data in Hadoop is distributed over several slave nodes in the cluster at the end of the map process there will be map output on every slave node and the key will be split over each of these nodes. We are going to write some code to add up these outputs in our reduce() method and for that to work each time the reduce method is called we need to have that full list of values for a particular key provided to that reduce() method. Suppose we wanted to add up the sample data, as shown in the above screenshot, here in the reduce() method, we need to find all the instances of our map output where the key is, lets say Agra, to be able to add them up but this is split over a number of nodes and reducer() method can only run on one node at a time. So here what we need is the Shuffle step to move the result of map() method around so that all the instances of a single key ended up on one node only.
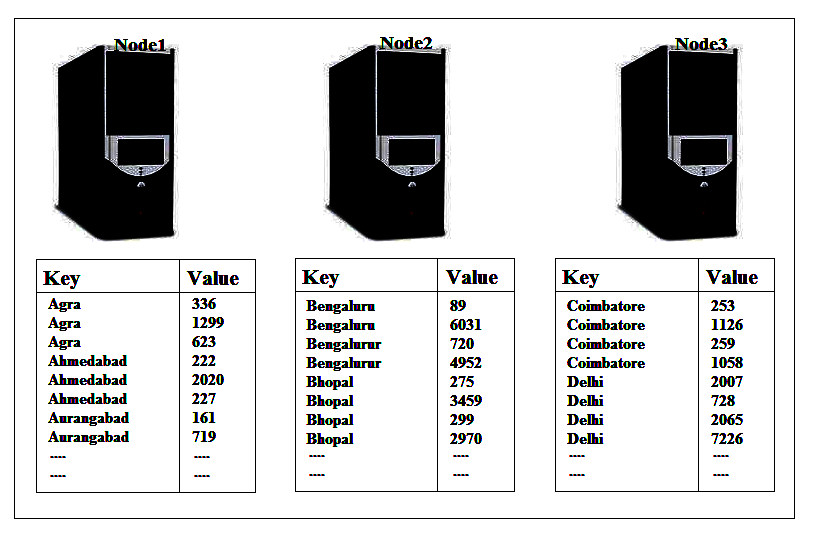
Doing so allows the reduce job to be safe splits up amongst the nodes. Doing the Shuffle means we can run reduce() on each node and we don’t have to worry about duplication of the data or only part of the data is being seen by reduce() method. Once the Shuffle step is completed, Hadoop then groups the values of each key together so, at the end of the Shuffle step, we will have input data to our reduce method on each node.
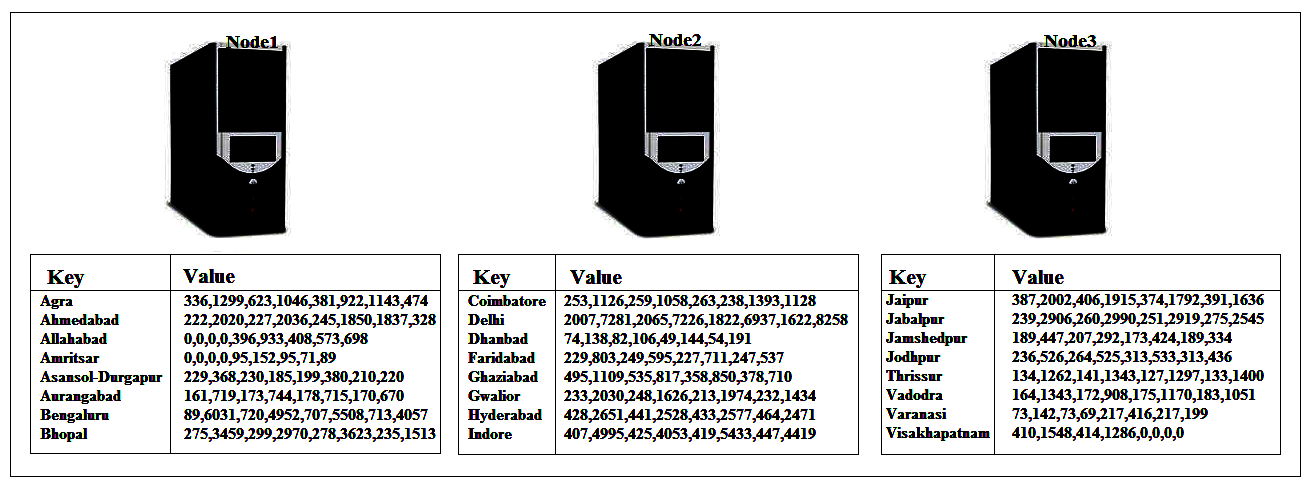
The input data will consist of lots of keys, each with the set of values, which will be roughly evenly distributed across the nodes. There will importantly no duplication of keys across the node, however. So each key appears only once in the whole list of keys on all the nodes. So the genuine process flow for a Hadoop job is:
We have to write the code for map & reduce but not for the Shuffle. Shuffle step doesn’t start until the map step completes and reduce step doesn’t start until the Shuffle step completes. Now least efficient part of these whole process tends to be Shuffle step.
Sort:
The set of intermediate keys on a single node is automatically sorted by Hadoop before they are presented to the Reducer. After the Shuffle step and before the Reduce step there is another step that happens automatically and that is why Hadoop job outputs the data in ordered key fashion. Sort step sorts only the keys and not the values. So the more precise genuine process flow for a Hadoop job is:

Note that Shuffle and Sort are not performed at all if you specify zero reducers (setNumReduceTasks(0)). Then, the MapReduce job stops at the map phase, and the map phase does not include any kind of sorting.
Combine
Imagine we have run our VowelAnalysis code on a large chunk of text in a cluster with lots of nodes. The map output at a particular moment will have lots of duplications pointing all the a’s, e’s, i’s and so on.
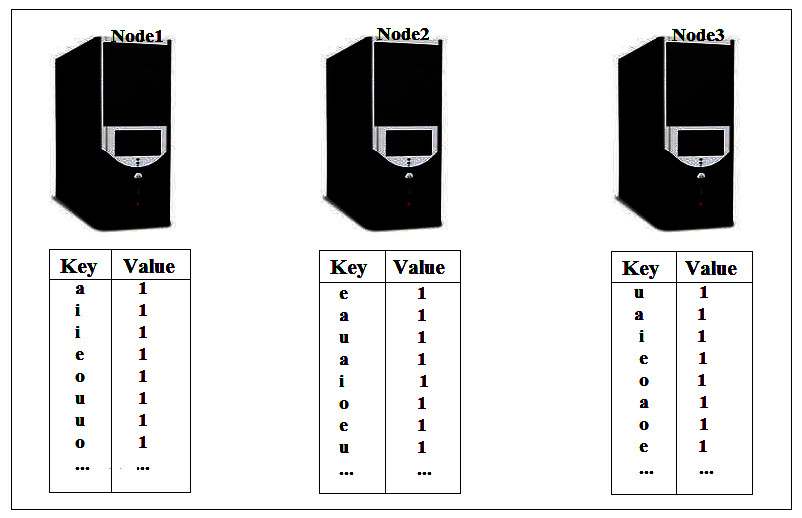
To move these map outputs across the cluster will take a quite long time. This takes all the nodes to talk to each other and there are lots of network traffic involved between those nodes. It would be better if we did an extra aggregation on each node to reduce our data before the Shuffle step takes place that would speed up the Shuffle and make our job run faster. if we added up all the 1’s on each machine at the end of the map process our data would look like a lot smaller:
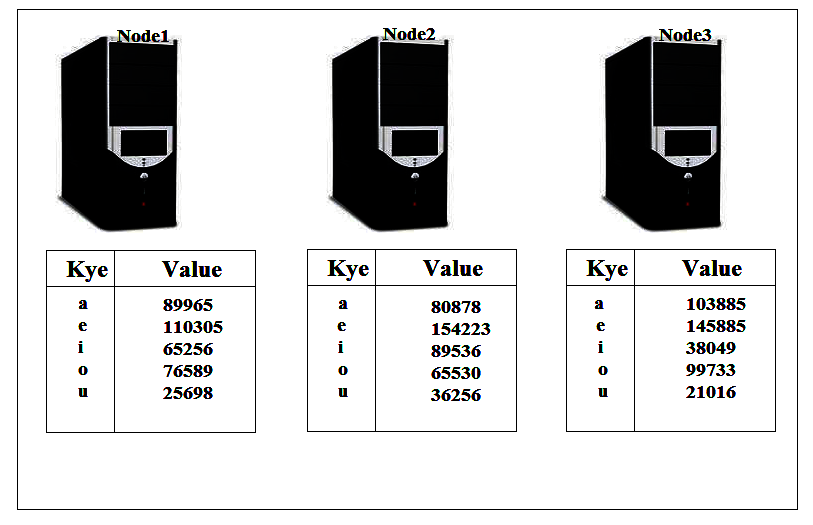
Clearly, there are far few items to shuffle around the network that means Shuffle step happen a lot quicker and also the number of items in each list to fed into reducer will also be fewer, so the reducer process will run more quickly too. We can add an extra step, like this, to the process is called the Combine step. So now our full process flow is:
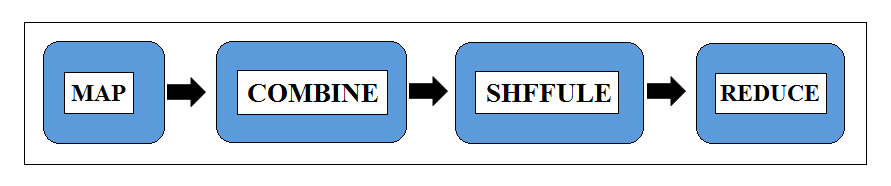
The syntax for Combine step is exactly as same as the of the Reduce step. For Combine class, we need to write a class which should extend Reduce class and implements the reduce() method.
import org.apache.hadoop.mapreduce.Reducer
public class Combine extends Reducer{
public void reduce(params){
//combine logic here
}
}
this makes sense because of the combine and reduce steps doing exactly the same things. They are taking a number of values for a single key and aggregating them together into a single value. In many cases, you don’t need to write an extra Combine step we can instruct the Hadoop that the Reduce Class can also be used as Combine Class. Doing this we will enable us to use the same code for both the Combine step and Reduce step. We can think of the Reduce and Combine doing the same thing but in the different scope. It feels like Combine aggregate data on the single machine and Reducer aggregate data across several machines this isn’t exactly how it works. They do exactly the same things. They both aggregate data on a single node but because Combine happens before Shuffle step and Reduce step happens after the Shuffle step, the scope is different. The more important point here is that during the Combine, it will reduce the amount of data that needed to be shuffled, which reduces the network traffic needed for shuffle, ended up speeding up our job. Normally our reduce code can be used as combine code.
Let’s take our VowelAnalysis as an example, the reduce step simply counts up the number of items so that will work as combine step too. Here in the combine step, we want to do a sub count on each of the number of the vowel before Shuffle and then a final total of the items after the Shuffle. The code for both of these steps looks identical. So now we have a four steps process but we need to code for only two of these steps: map() and reduce() methods. The reduce() method might also be reused as combine() method or we can also create an extra combine method if the existing reduce() won’t fulfil the requirements.
So let’s see these in action, we have already done the VowelAnalysis example on Bible text and we have executed it in both the standalone and pseudo-distributed mode. The job took a little time. Now let’s add up a Combine step and see if it speeds up the overall process. Even though we are running on a single node, so there is no real network traffic to save, we would still see some saving in total time taken for the job because there will be less disk writing will be needed in the reduce step if we have Combine.
In order to use Combine step in the job, we need to use a configuration method:
setCombinerClass(CombinerClassName.class)
in our job configuration class. Here we will use the existing Reduce class as Combine class so it will go like this:
job.setCombinerClass(VowelAnalysisReducer.class);
The full working code is given below:
/**
* A MapReduce WordAnalysis Job in Hadoop using new API.
* Problem Statement: We have given a text file or many text files and we have to calculate the total number of occurrences of each
* vowels in the file(s).
*/
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/**
* @author course.dvanalyticsmds.com
*
*/
public class VowelAnalysis{
public static class VowelAnalysisMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//Do the map-side processing i.e., write out key and value pairs
//Remove all punctuation and place in lower case
String line = value.toString().replaceAll("\\p{Punct}","").toLowerCase();
char[] chars = line.toCharArray();
for(char letter : chars){
switch(letter){
case 'a':
case 'e':
case 'i':
case 'o':
case 'u':
context.write(new Text(String.valueOf(letter)), new LongWritable(1));
}
}
}
}
public static class VowelAnalysisReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
public void reduce(Text key, Iterable<LongWritable> values,
Context context) throws IOException, InterruptedException {
//Do the reduce-side processing i.e., write out the key and value pairs
Iterator<LongWritable> it = values.iterator();
long sum = 0;
while(it.hasNext()){
//Do some calculation
sum += it.next().get();
}
context.write(key, new LongWritable(sum));
}
}
public static void main(String[] args) throws Exception {
/**Configure the job**/
Path in = new Path(args[0]); //Create Path variable for input data
Path out = new Path(args[1]); //Create Path variable for output data
Configuration conf = new Configuration(); //Create an instance Configuration Class
Job job = Job.getInstance(conf); //Create an instance of Job class using the getInstance()
job.setOutputKeyClass(Text.class); //Set the "key" output class for the map
job.setOutputValueClass(LongWritable.class); //Set the "value" output class for the map
job.setMapperClass(VowelAnalysisMapper.class); //Set the Mapper Class
job.setReducerClass(VowelAnalysisReducer.class); //Set the Reducer Class
job.setCombinerClass(VowelAnalysisReducer.class); //Set the Combiner Class if applicable.
job.setInputFormatClass(TextInputFormat.class); //Set the InputFormat Class
job.setOutputFormatClass(TextOutputFormat.class); //Set the OutputFormat Class
FileInputFormat.addInputPath(job, in); //Specify the InputPath to the Job
FileOutputFormat.setOutputPath(job, out); //Specify the OutputPath to the Job
job.setJarByClass(VowelAnalysis.class); //set the JobControl class name in the JAR file
job.setJobName("VowelsCount"); //set a name for you job
job.submit(); //submit your job to Hadoop for execution
}
}
I have executed the VowelAnalysis without combine step in pseudo-distributed mode and below is the screenshot of the user interface for Hadoop,
https://localhost:8088
, to see the application status:
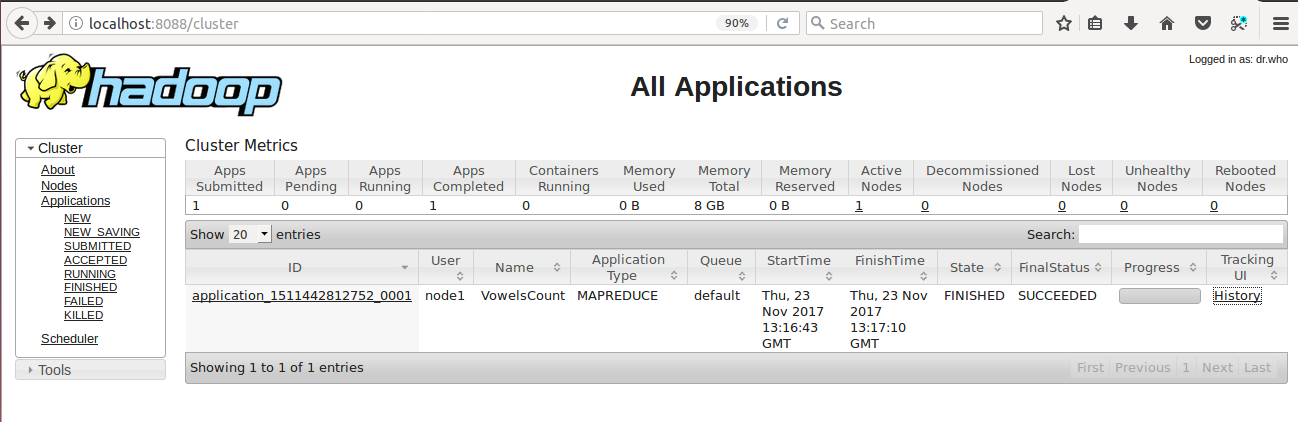
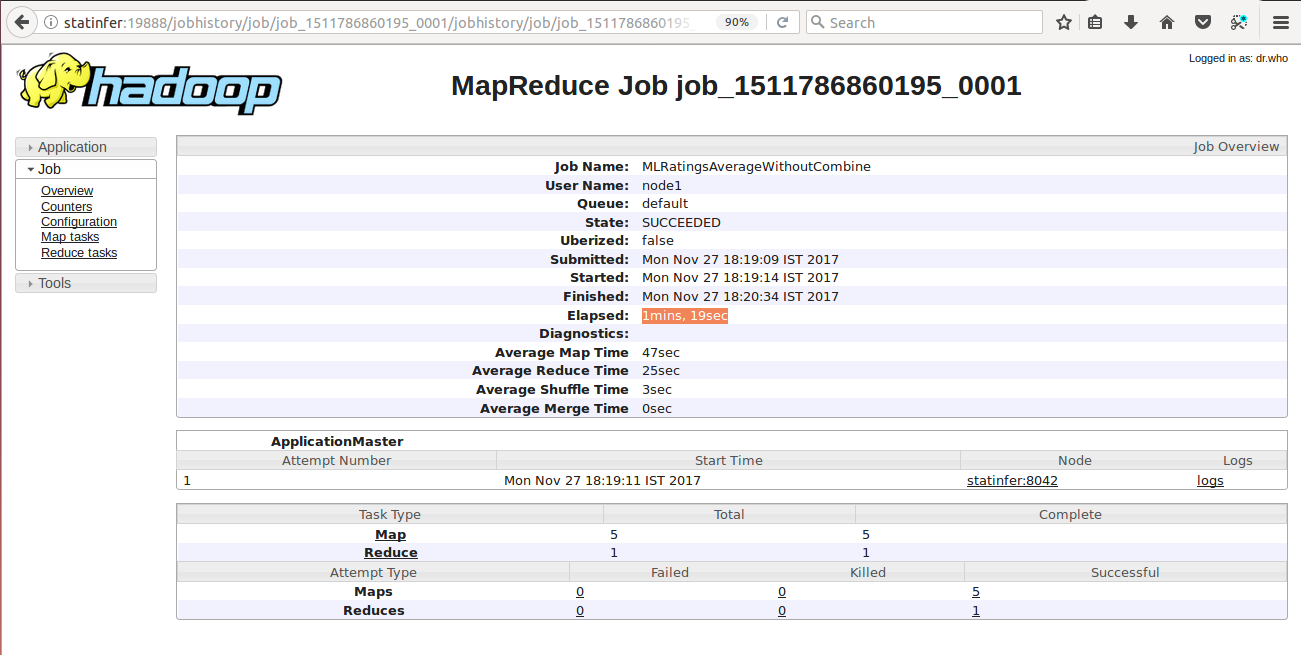
Now click on the History link to get the more precise information about the job. Below screenshot shows the history of my first job i.e., VowelAnalysis without combine step:
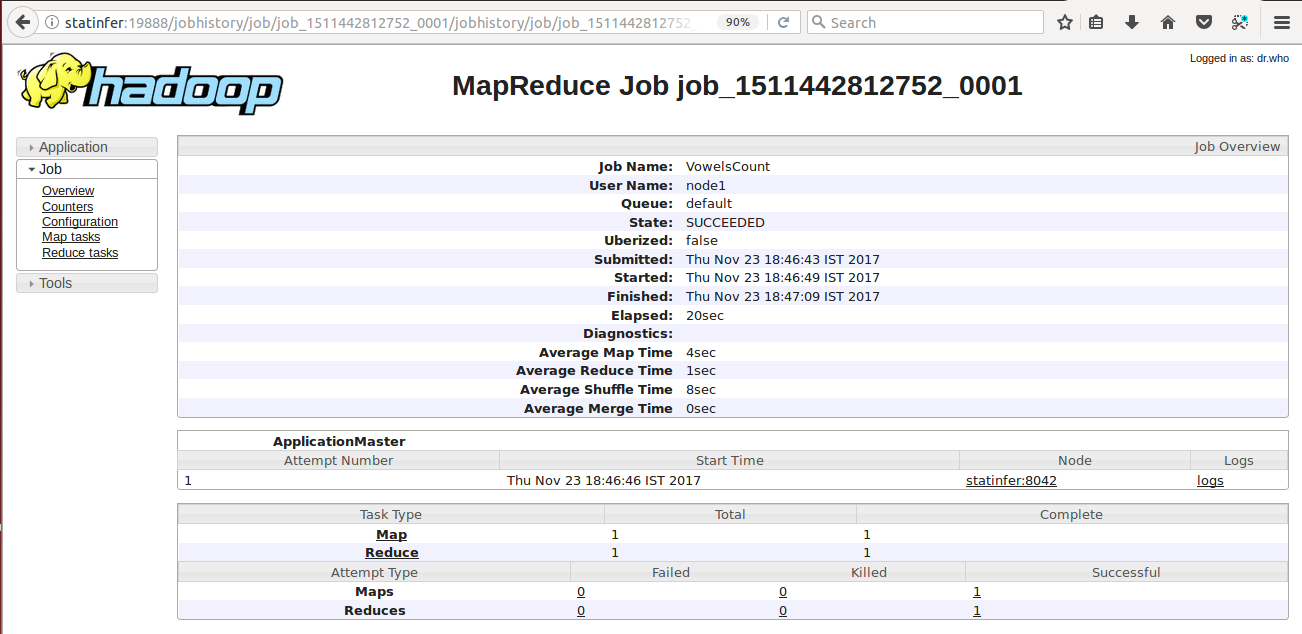
Here we can see the
Elapsed: 20 Seconds
which means the job took this much of time to finish and the
Average Shuffle Time is 8
seconds.
Note:
Sometimes when you click on the History link, the job history page doesn’t appear, as a solution you can use the
localhost
at the place of the domain name, in my case its statinfer, in the URL.
So instead of this URL:
http://statinfer:19888/jobhistory/job/job_1511442812752_0001/jobhistory/job/job_1511442812752_0001
I can try this one:
http://localhost:19888/jobhistory/job/job_1511442812752_0001/jobhistory/job/job_1511442812752_0001
Again I have executed the VowelAnalysis but this time I have used the Combine step, the source code is given above, in pseudo-distributed mode and below is the screenshot of the user interface for Hadoop using
https://localhost:8088
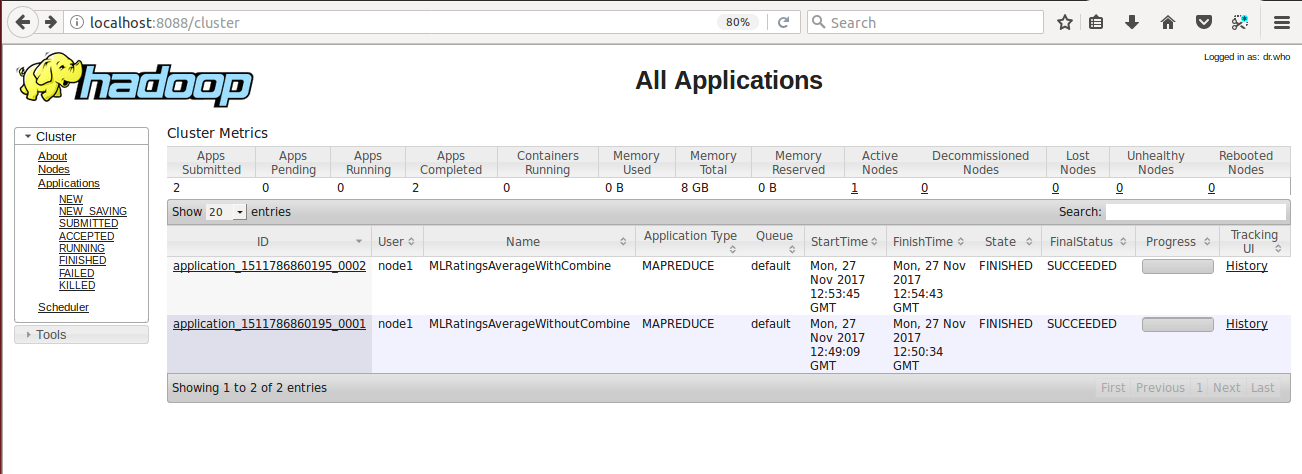
, here you need to refresh the tab, to see the Application status. Below is the screenshot of the Application status of two jobs: application_1511442812752_0001 is the job without combine step an application_1511442812752_0002 is the job with combine step.
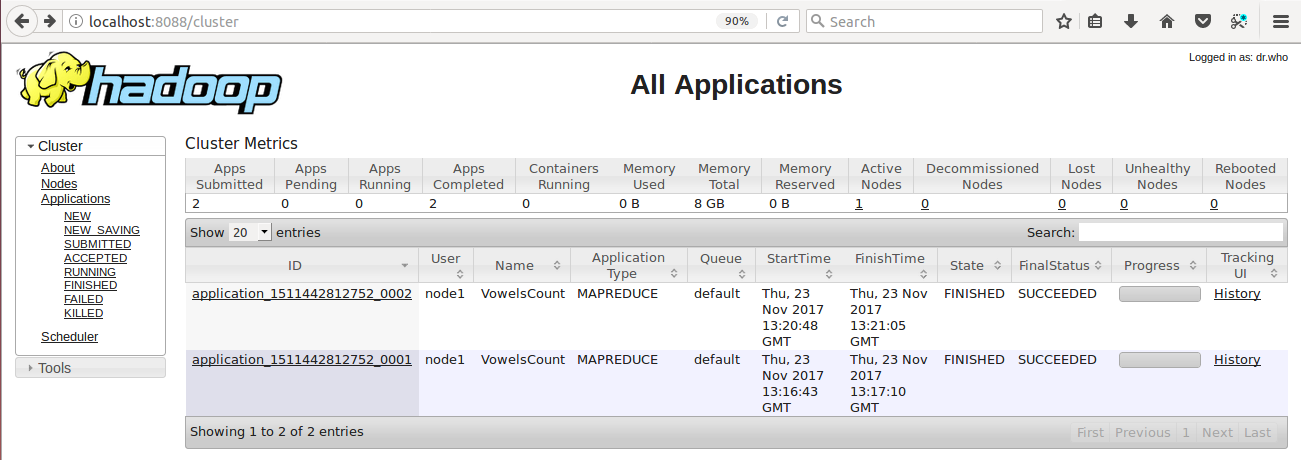
Now click on the History link of application_1511442812752_0002 to get the more precise information about the job. Below screenshot shows the history for my second job i.e., VowelAnalysis with combine step:
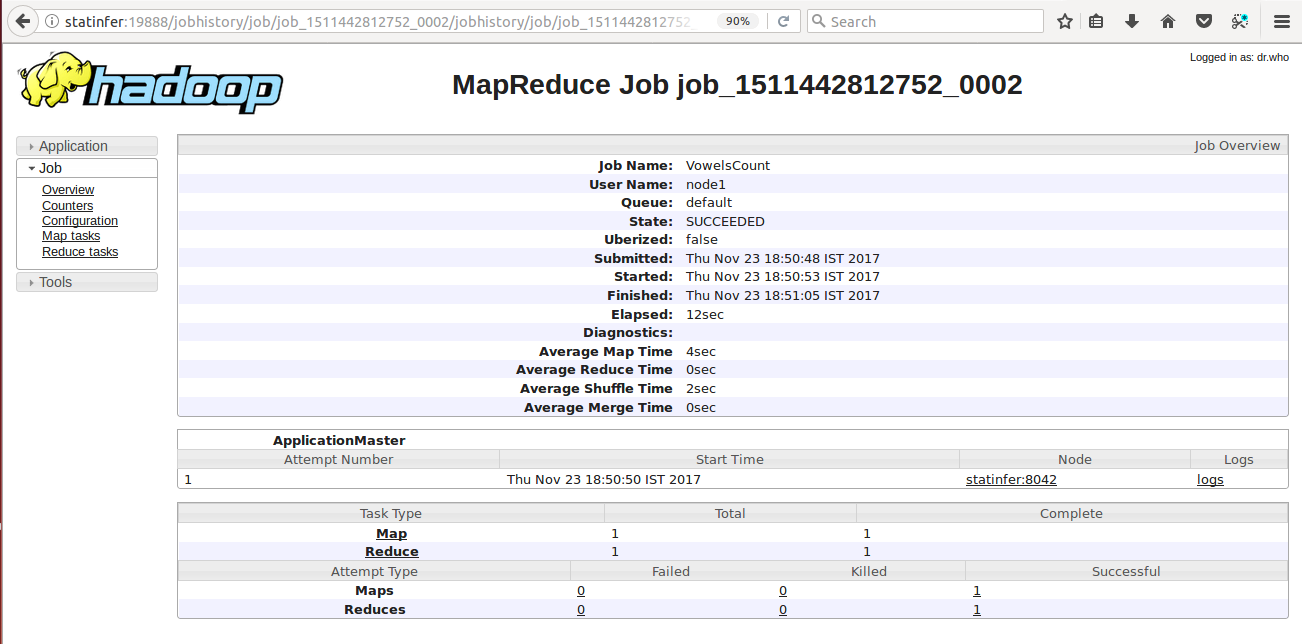
Here we can see the
Elapsed: 12 Seconds
which means the job took this much of time to finish and the
Average Shuffle Time is 2 Seconds
and these readings are the less than the first job we were seen earlier. Here we got the benefit of reduced disk reading and writing but not the benefit of the reduced network because of the pseudo-distributed mode of Hadoop on a single node. We can see the greater benefits on a fully distributed cluster with a very large dataset. So after analysing the history of these two jobs, we can observe the impact of Combine step in the MapReduce job.
What have we done? Well, we have used the same reduce() method as combine() method for this vowel count job. Let’s go through the reduce() method and see what it’s actually doing:
public void reduce(Text key, Iterable<LongWritable> values,
Context context) throws IOException, InterruptedException {
//Do the reduce-side processing i.e., write out the key and value pairs
Iterator<LongWritable> it = values.iterator();
long sum = 0;
while(it.hasNext()){
//Do some calculation
sum += it.next().get();
}
context.write(key, new LongWritable(sum));
}
Here reduce() method takes the key of Text and value of LongWritable and outputs key of Text and value of LongWritable. It simply adds up the number of items provided. So this worked absolutely fine as the combine() too. Even if we have the cluster with lots of nodes, we can run the exact same code as combine step and it will reduce the number of items that fed into Shuffle process. So we told our VowelAnalysis this reduce() method is also going to use as the combine() method and for that, we did a very simple step. We went to the job configuration section and configured our job to have a combine step as: job.setCombinerClass(VowelAnalysisReducer.class); here we have passed in a class which is going to be used as Combiner. This was the single configuration line to add in to add combine step to our job.
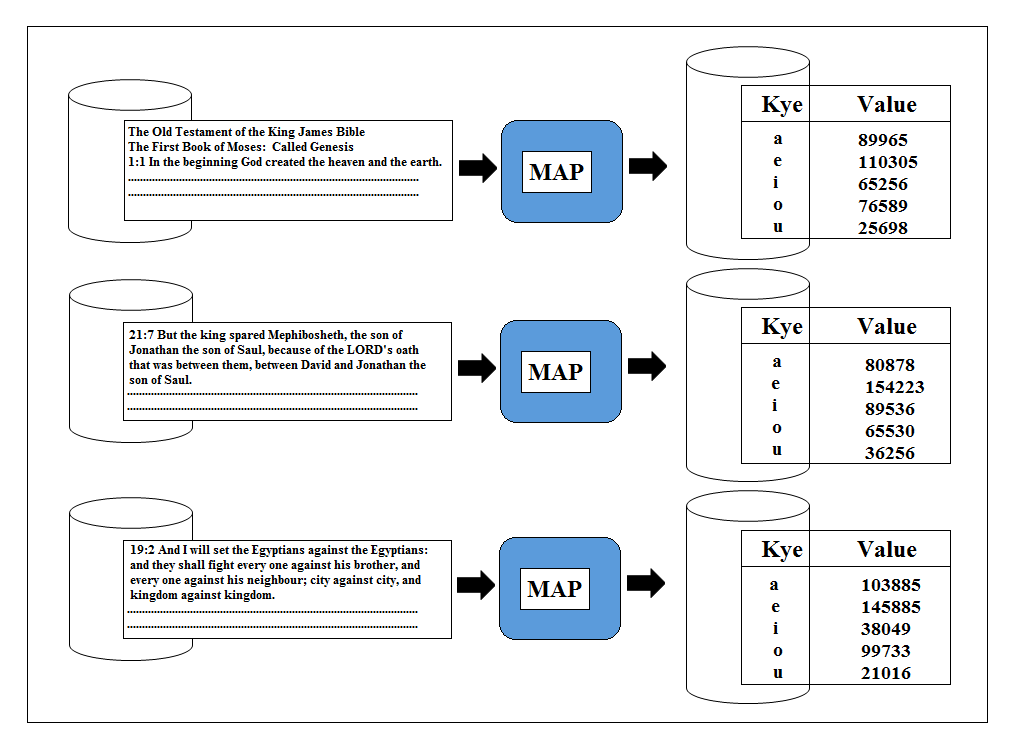
So we have already executed the jobs with combine step and without combine step and seen the job history. Now let’s see what will be the overall process flow when we will run the same job with the combine step in a cluster with lots of node on. We will have our input data with a lot of texts in it and at the end of the map process the output will be a number of lists of a’s, e’s, i’s, o’s and u’s all having the value of 1.
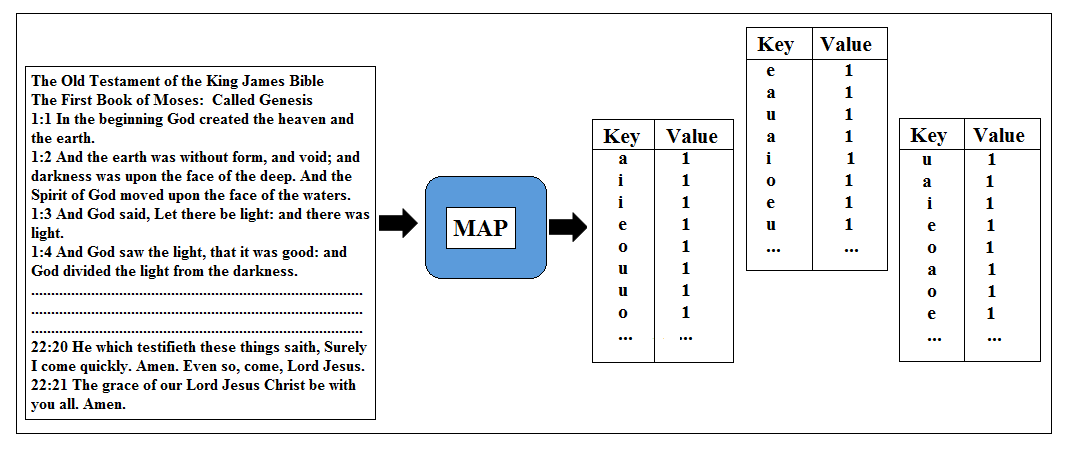
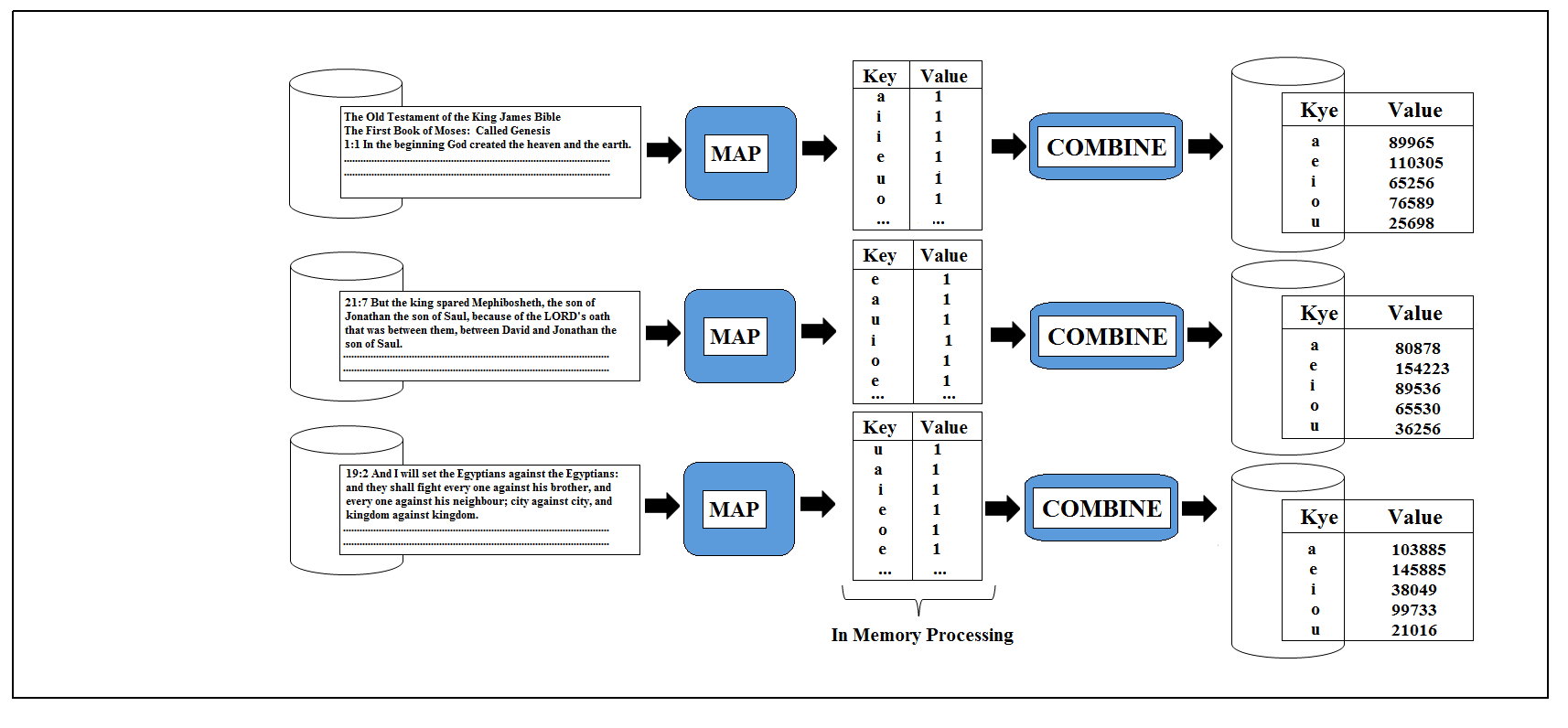
We then have our new combine step, which is going to be creating the subtotal for each of this list.
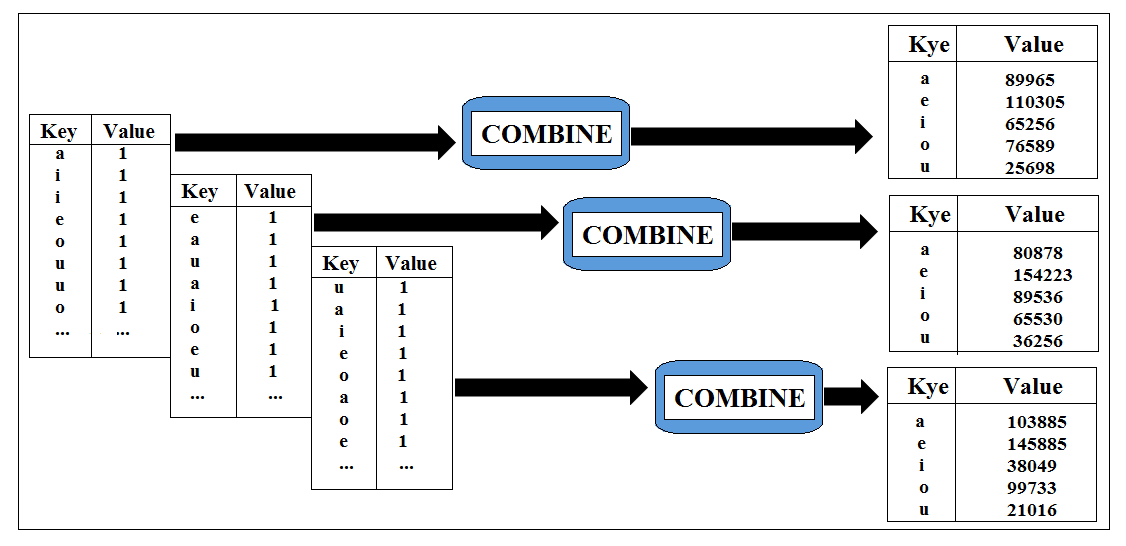
this will result in the much smaller list all with one a, e, i, o and u but this time much bigger value next to them. The Shuffle step then takes place which will combine together the values from the list we got.
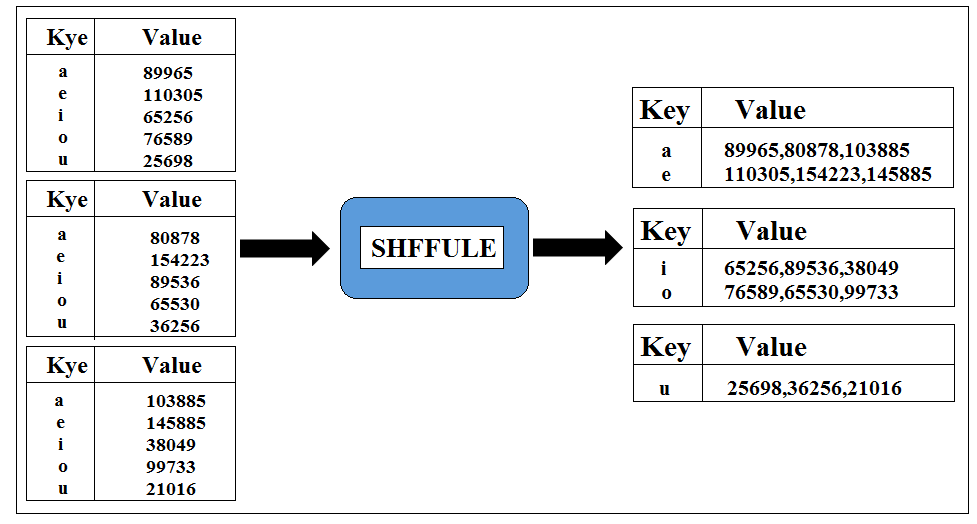
and finally, the reduce step will add up those values and give us the output that we are looking for.
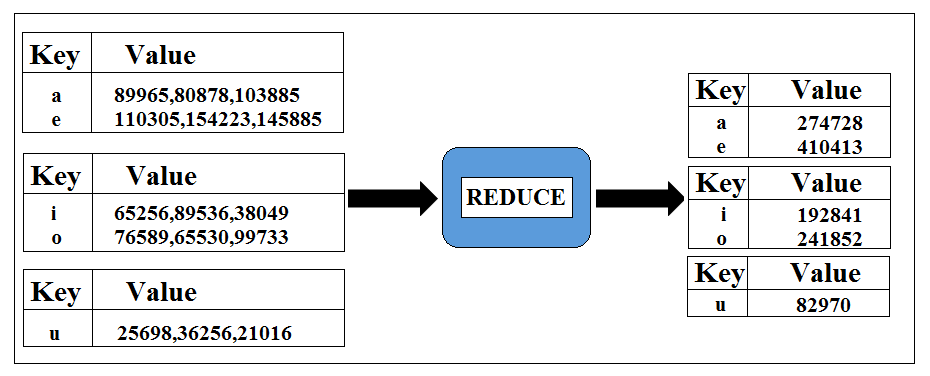
So at both points: combine and reduce we are doing exactly the same thing. we are adding up all the numbers for each key.
Now it’s important to understand that the combine step may or may not run and if it does run, it might run more than once. Hadoop decides whether or not run the combine step based on the amount of data. So even though we supply a combine step to our job, it may not get used. If we don’t have a combine step then Hadoop loads input data from the disk in the map process, does the processing keeping all the results in the memory and then writes out the results on the disk at the end. If we have too much input data to be read in a single job run, our input data is to be split into sections resulting in the map task to run in the number of times by load again the parts of data each time.
When we have combine step, this comes into action after the mapping process but before the data written out to the disk. Hadoop runs the combine using the data in memory to reduce what gets written out. So there will be an instance when combine runs multiple times on a node and if there isn’t sufficient data to justify to reduce the volume, Hadoop might not decide to run it.
It is important to understand that the map, combine and reduce code must be able to work together so there is the same result to obtain if the combine step runs or it doesn’t. We can’t write code in the combine step which changes data it should only aggregate the data. If the reduce method changes the data then it won’t be a valid combine step. We will see such example shortly in this section. The other thing is that the input and output data from a combine step must match exactly.
public class Combine extends Reducer<Text, LongWritable, Text, LongWritable>
so if the input to combine step is key of Text and value of LongWritable then the output must also be a key of Text and a value of LongWritable. Furthermore, the input to a combine step must also match with the output from the map step and the output from the combine step must also match with the input to reduce step.
public class Map extends Mapper<Text, LongWritable, Text, LongWritable>
public class Combine extends Reducer<Text, LongWritable, Text, LongWritable>
public class Combine extends Reducer<Text, LongWritable, Text, Text>
in the example above, the reduce step has output from the different format than the input so it won’t work as combine step.
Let’s look at the different example now which would require a different combine method to the reduce method. In this example, we are going to analyse one of the most known public domain data set: The Movie Lens Dataset”. You can download the ml-latest.zip (size: 224 MB) dataset which is available here
.
First, we will calculate the average rating of each movie without combine step and then the average rating of each movie with combine step. So let’s go!!
When we calculate the average without combine step, the process flow will look like the image given below: we will provide input to the map, then map will output the MovieId and Ratings for each movie, map outputs will get shuffled and sorted and finally in the reduce phase we will calculate the average for each key, which is MovieId, and write them out as our final result.
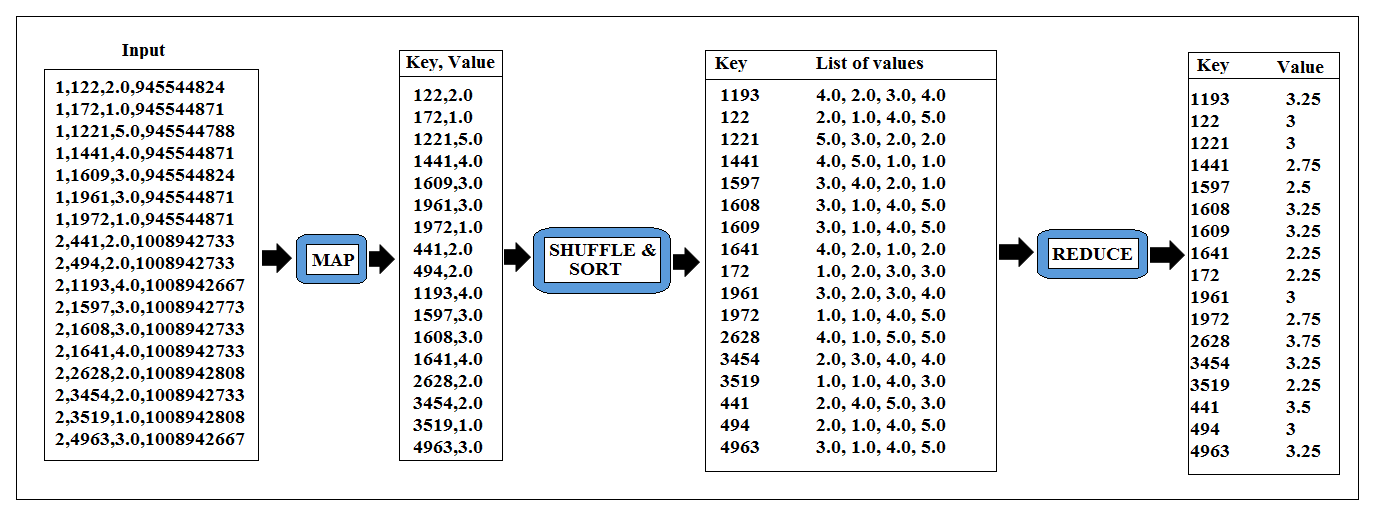
In a fully distributed mode, if we use combiner then it will fast up the shuffling process and if don’t use the combine step the shuffling will be very inefficient because each of the nodes in the cluster will have few keys with very large value at the end of the mapping process.
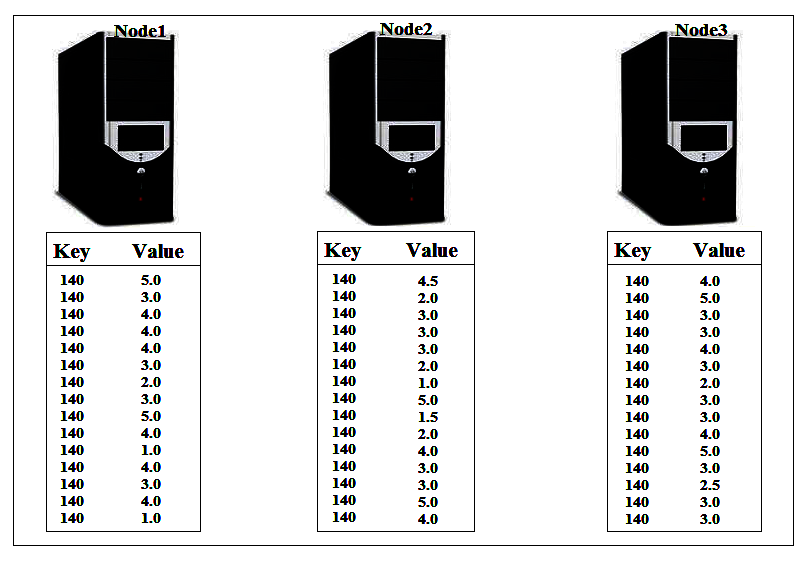
So in such case we can make shuffling efficient by using Combiner but here is a problem, if we use existing Reducer Combiner we might get wrong results:
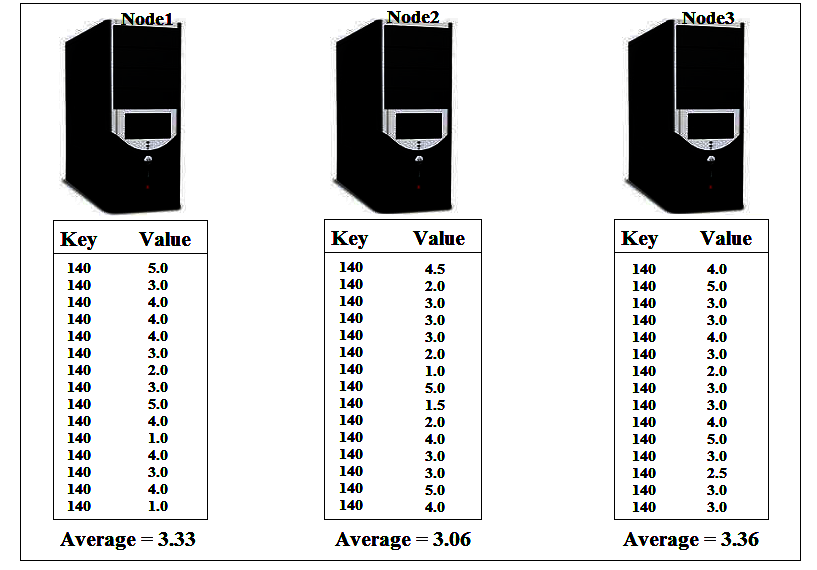
The average for these datapoints that Reducer would caluculate is: (5 + 3+ 4 + 4 + 4 + 3 + 2 + 3 + 5 + 4 + 1 + 4 + 3 + 4 +1 + 4.5 + 2 + 3 + 3 + 3 + 2 + 1 + 5 + 1.5 + 2 + 4 + 4 + 5 + 3 + 3 + 4 + 3 + 2 + 3 + 3 + 4 + 5 + 3 + 2.5 + ) / 39 =
3.217948718
. But if we use the existing redcue() method as combiner at each node then it will calculate the average of the data that available on each node. For the first node it is 3.333333333, for the second node 2.818181818 and for the third node it is 3.423076923 . Now when we run reduce on these three datapoints, we will get the average: (3.333333333 + 2.818181818 + 3.423076923) / 3 =
3.191530691
. So the reduce() method will give us incorrect answer and hence we can’t use the same reduce() method as combine() method. Here we need to change the combine() method to produce the total of the ratings and the number of the ratings. Then the reduce() method will use these two values to calculate the correct average. Here we need to change our map() method to inorder to cop-up with combine() and reduce() methods. Now, our map() method need to produce key as MovieId and value which is made up of two items: the “rating” and “1”. The entire process flow is give below in the diagrams:
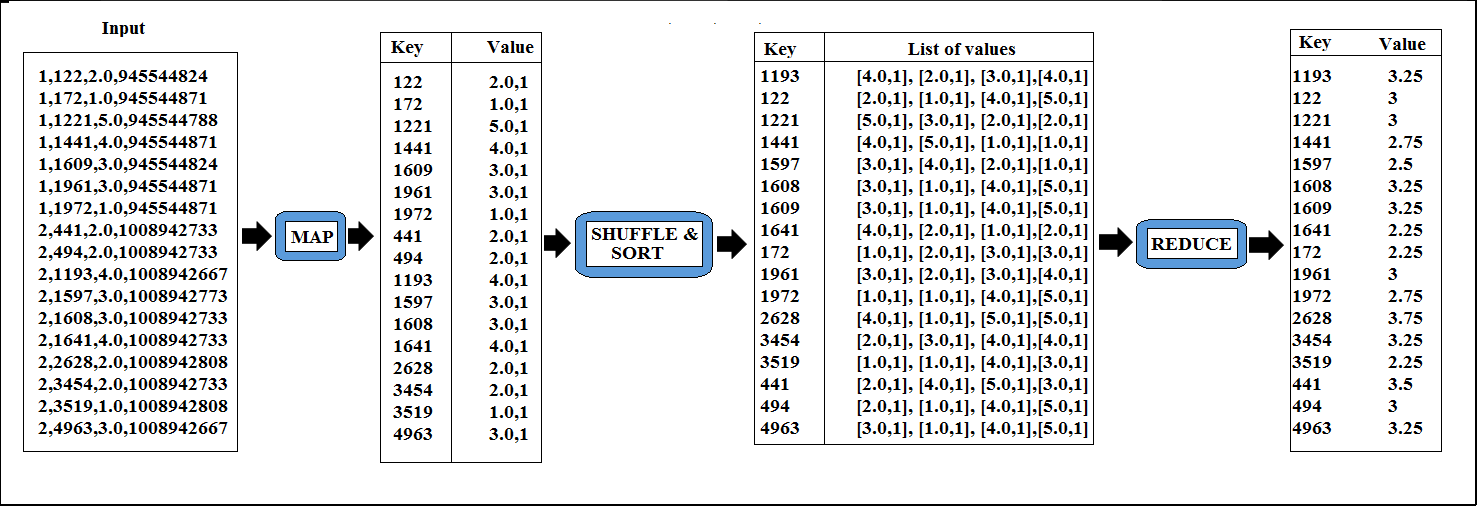
Figure: Process Flow With Combine Step
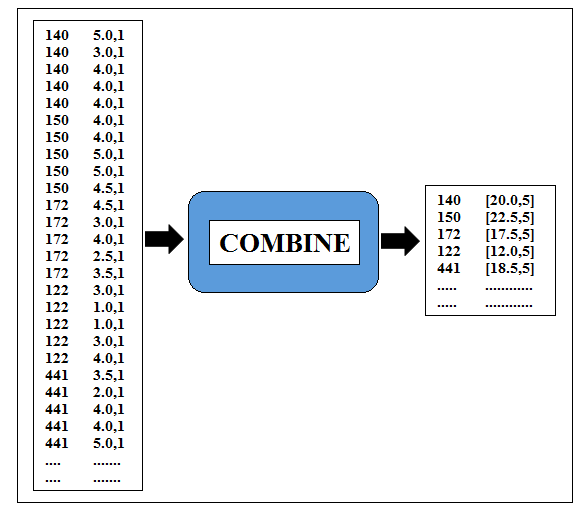
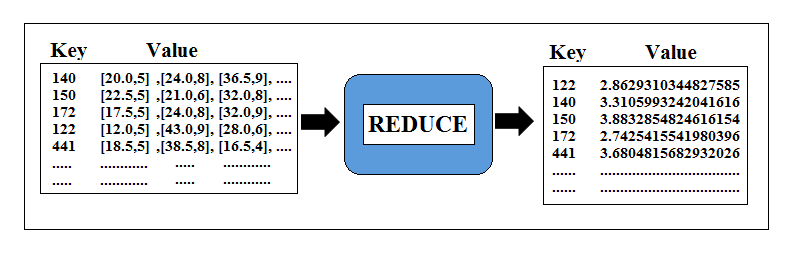
As we have learnt earlier combiner might or might not run, if it won’t run for this particular job, the result would be correct.
Source code to calculate the average without combine step:
//A MapReduce Program to average analysis without combine step on ratings.csv of the ml-latest data set.
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/**
* @author course.dvanalyticsmds.com
*
*/
public class MLRatingsAverageWithoutCombine {
public static class MLRatingsMapper extends Mapper<LongWritable, Text, Text, Text> {
public void map(LongWritable key, Text values, Context context)
throws IOException, InterruptedException {
//Do the map-side processing i.e., write out key and value pairs
String sValue = values.toString();
String[] value = sValue.split(",");
context.write(new Text(value[1]), new Text(value[2]+",1"));
}
}
public static class MLRatingsReducer extends Reducer<Text, Text, Text, DoubleWritable> {
public void reduce(Text key, Iterable<Text> values,
Context context) throws IOException, InterruptedException {
//Do the reduce-side processing i.e., write out the key and value pairs
Iterator<Text> it = values.iterator();
Double totalRatings = 0d;
Long numberOfViewers = 0l;
while(it.hasNext()){
String value = it.next().toString();
String[] sValue = value.split(",");
totalRatings += Double.valueOf(sValue[0]);
numberOfViewers += Long.valueOf(sValue[1]);
}
Double average = totalRatings / numberOfViewers;
context.write(key, new DoubleWritable(average));
}
}
public static void main(String[] args) throws Exception {
/**Configure the job**/
Path in = new Path(args[0]); //Create Path variable for input data
Path out = new Path(args[1]); //Create Path variable for output data
Configuration conf = new Configuration(); //Create an instance Configuration Class
Job job = Job.getInstance(conf); //Create an instance of Job class using the getInstance()
job.setOutputKeyClass(Text.class); //Set the "key" output class for the map
job.setOutputValueClass(Text.class); //Set the "value" output class for the map
job.setMapperClass(MLRatingsMapper.class); //Set the Mapper Class
job.setReducerClass(MLRatingsReducer.class); //Set the Reducer Class
//job.setCombinerClass(MyReduceClass.class); //Set the Combiner Class if applicable.
job.setInputFormatClass(TextInputFormat.class); //Set the InputFormat Class
job.setOutputFormatClass(TextOutputFormat.class); //Set the OutputFormat Class
FileInputFormat.addInputPath(job, in); //Specify the InputPath to the Job
FileOutputFormat.setOutputPath(job, out); //Specify the OutputPath to the Job
job.setJarByClass(MLRatingsAverageWithoutCombine.class); //set the JobControl class name in the JAR file
job.setJobName("MlMovieRatingsAverage"); //set a name for you job
job.submit(); //submit your job to Hadoop for execution
}
}
Source code to calculate the average with combine step:
//A MapReduce Program to average analysis with the combine step on ratings.csv of the ml-latest data set.
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/**
* @author course.dvanalyticsmds.com
*
*/
public class MLRatingsAverageWithCombine {
public static class MLRatingsMapper extends Mapper<LongWritable, Text, Text, Text> {
public void map(LongWritable key, Text values, Context context)
throws IOException, InterruptedException {
//Do the map-side processing i.e., write out key and value pairs
String sValue = values.toString();
String[] value = sValue.split(",");
context.write(new Text(value[1]), new Text(value[2]+",1"));
}
}
public static class MLRatingsCombiner extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values,
Context context) throws IOException, InterruptedException {
//Do the reduce-side processing i.e., write out the key and value pairs
Iterator<Text> it = values.iterator();
Double totalRatings = 0d;
Long numberOfViewers = 0l;
while(it.hasNext()){
String value = it.next().toString();
String[] sValue = value.split(",");
totalRatings += Double.valueOf(sValue[0]);
numberOfViewers += Long.valueOf(sValue[1]);
}
context.write(key, new Text(totalRatings.toString() + ","+ numberOfViewers.toString()));
}
}
public static class MLRatingsReducer extends Reducer<Text, Text, Text, DoubleWritable> {
public void reduce(Text key, Iterable<Text> values,
Context context) throws IOException, InterruptedException {
//Do the reduce-side processing i.e., write out the key and value pairs
Iterator<Text> it = values.iterator();
Double totalRatings = 0d;
Long numberOfViewers = 0l;
while(it.hasNext()){
String value = it.next().toString();
String[] sValue = value.split(",");
totalRatings += Double.valueOf(sValue[0]);
numberOfViewers += Long.valueOf(sValue[1]);
}
Double average = totalRatings / numberOfViewers;
context.write(key, new DoubleWritable(average));
}
}
public static void main(String[] args) throws Exception {
/**Configure the job**/
Path in = new Path(args[0]); //Create Path variable for input data
Path out = new Path(args[1]); //Create Path variable for output data
Configuration conf = new Configuration(); //Create an instance Configuration Class
Job job = Job.getInstance(conf); //Create an instance of Job class using the getInstance()
job.setOutputKeyClass(Text.class); //Set the "key" output class for the map
job.setOutputValueClass(Text.class); //Set the "value" output class for the map
job.setMapperClass(MLRatingsMapper.class); //Set the Mapper Class
job.setCombinerClass(MLRatingsCombiner.class); //Set the Combiner Class if applicable.
job.setReducerClass(MLRatingsReducer.class); //Set the Reducer Class
job.setInputFormatClass(TextInputFormat.class); //Set the InputFormat Class
job.setOutputFormatClass(TextOutputFormat.class); //Set the OutputFormat Class
FileInputFormat.addInputPath(job, in); //Specify the InputPath to the Job
FileOutputFormat.setOutputPath(job, out); //Specify the OutputPath to the Job
job.setJarByClass(MLRatingsAverageWithCombine.class); //set the JobControl class name in the JAR file
job.setJobName("MLRatingsAverage"); //set a name for you job
job.submit(); //submit your job to Hadoop for execution
}
}
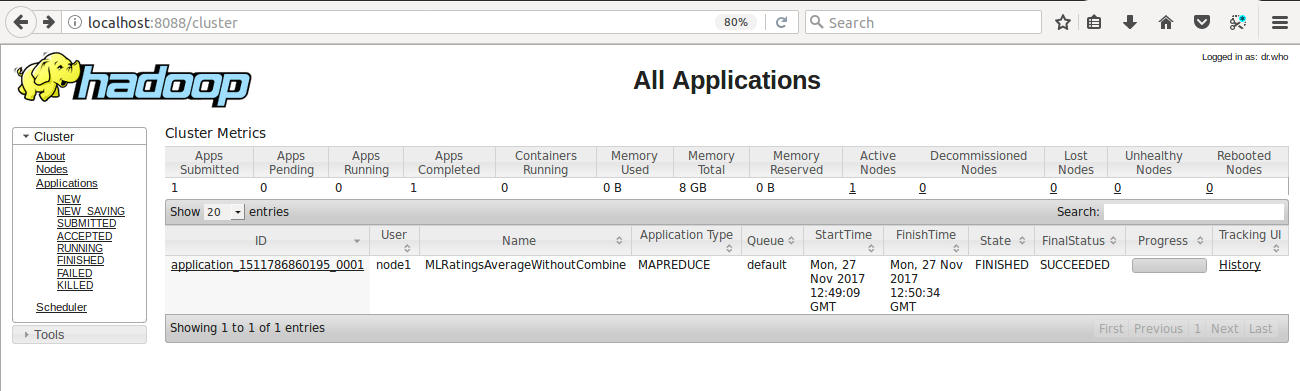
Let’s run the following job one bye one in pseudo-distributed mode and analyse the user screen:
$ hadoop jar FirstHadoopApp.jar MLRatingsAverageWithoutCombine ratings.csv ml-average-without combine
User Screen of Hadoop for Job 1 i.e., MLRatingsAverageWithoutCombine
$ hadoop jar FirstHadoopApp.jar MLRatingsAverageWithCombine ratings.csv ml-average-withcombine
User Screen of Hadoop for Job 1 i.e., MLRatingsAverageWithCombine
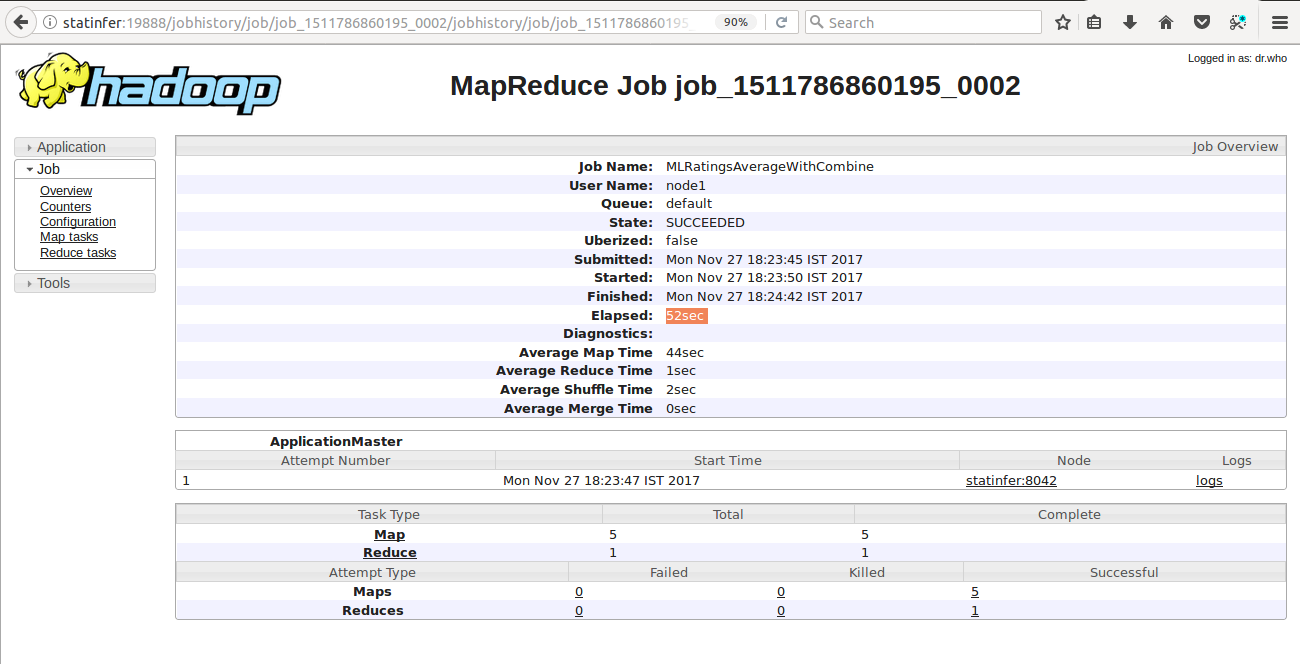
As both of these jobs are executed in pseudo-distributed mode, we won’t able to get the more advantages of Combine step, as we have discussed earlier, but when you will run both of these jobs in fully distributed mode, you will see the differences.
Exercise to Complete:
- Build a MapReduce job to calculate the average accident for each city on the accident dataset.
- Add in a combine step and re-execute the job, check the results are the same and see how long it took to execute.