In this section, we will learn about how MapReduce works and how to break up a problem into MapReduce solution.
So let’s start
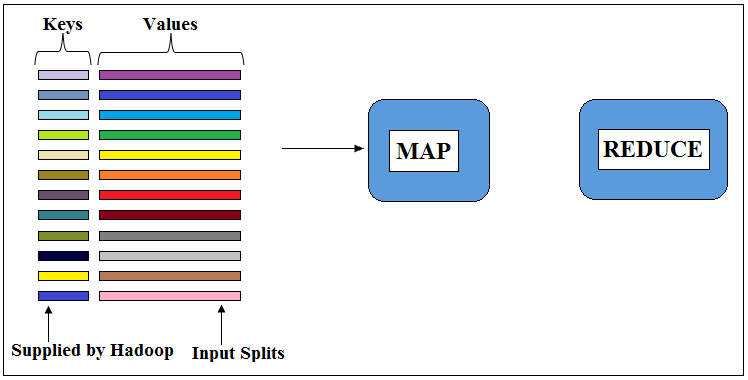
Figure 1: Input to Mapper in the form of Keys and Values
In MapReduce input to Maps are split. A Split contains several records and each record goes through same Mapper one bye one. The map method receives input in the form of keys and values and it outputs in the form of keys and values as well. At the time of input, Hadoop supplies unique key for every record and by default, it is a byte offset from start of the file. As a programmer, we have full control over keys and values being supplied to the map and reduce methods. We will learn how to supply customised keys and values to map and reduce methods later in the course.
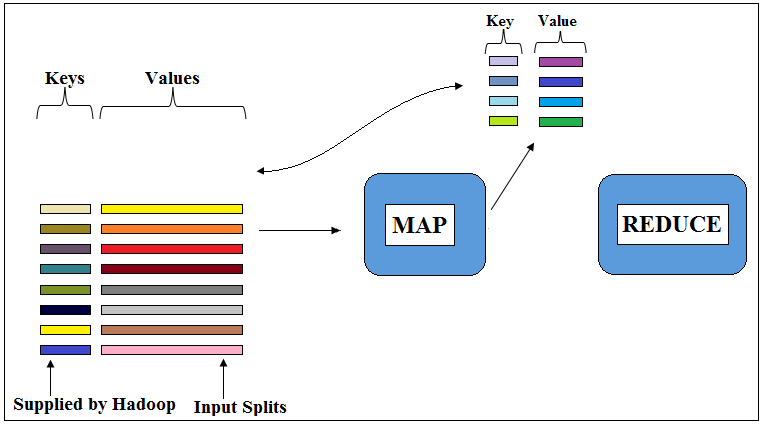
Figure 2: Output from Mapper in the form of Keys and Values
Map process keys and values one after other to produce zero, one or more key and value pairs. So, Map receives key, value pairs process them and output key, value pairs. Both input and output key, value pairs can be same or different. The input and output key, value pairs would be same if default Mapper is used. Default Mapper is also known as Identity Mapper which does nothing but copies input key, value pairs to output key, value pairs without any intermediate processing. While input to Map generally has unique keys, the output of Map generally has non-unique keys. The map method is designed in this way to output the key, value pairs so that it will be helpful later in the intermediate Shuffle & Sort phases. Hadoop sorts the data on the basis of a key. So the main purpose of Map method is to divide the input records into keys and values in such a way that the values when put together for the same key start to make sense.
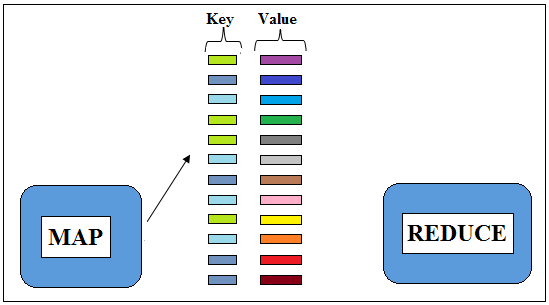
Figure 3: Output from Mapper in the form of Keys and Values
So the whole input records are processed and output is created. This output is also called as Intermediate Data. The Intermediate Data is sorted and shuffled on the basis of keys so that all the values with the same key are put together.
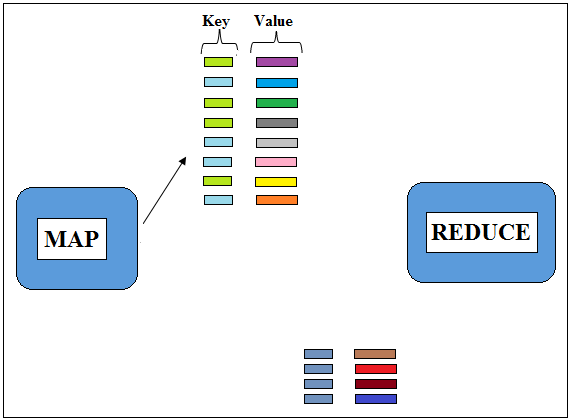
Figure 4.1: Values with same key are put together
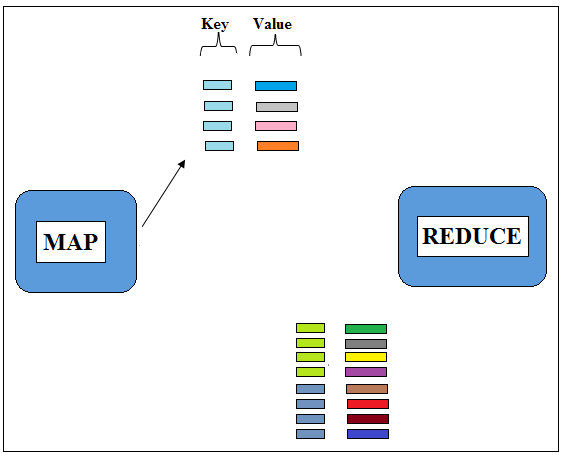
Figure 4.2: Values with same key are put together
Figure 4.3: Values with same key are put together
Now, these Intermediate Data fed into Reducer for further processing. The intermediate key, value pairs would be created by several maps. So it is necessary for the MapReduce Framework that the particular Reducer gets all the values for a particular key.
Figure 4.3: Output from Reducer in the form of Keys and Values
The whole mechanism of sorting the data and sending them over the network is managed by Hadoop Framework itself. Unlike Mapper, Reducer receives input as key and list of values associated with that key. Here values for each key would be unordered.
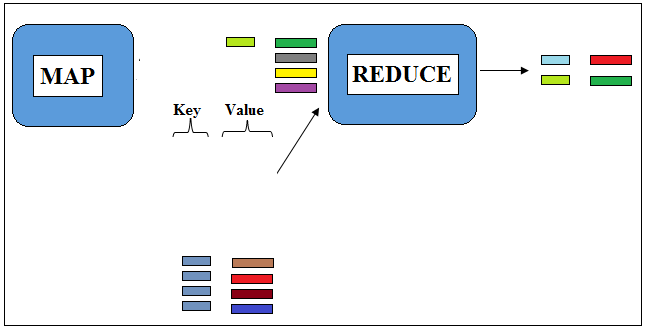
Figure 4.3: Output from Reducer in the form of Keys and Values
The reduce method is called once for each key and processes each value one by one. For each key and list of values, a reducer may choose to produce zero, one or more key, value pairs. The output produced by reducer would be ordered by key because it receives inputs in a key-ordered manner.
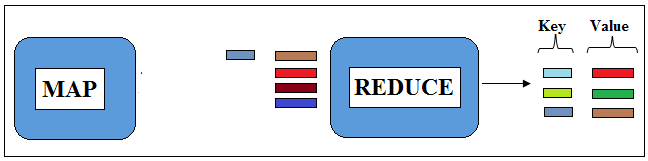
Figure 4.3: Output from Reducer in the form of Keys and Values
Breaking a Problem in MapReduce Solution
Now let’s understand how to break a problem into MapReduce solution. Here the basic trick you can apply is Reverse Engineering: identify how the final output should be, then you should be able to find out how the input to Reducer should be which in turn would help you to find out the Key. Identifying the Keys solves half of the problem then you can find how the input data should be broken into Keys and Values by Map and thus find the solution.
Here we have a problem to solve using MapReduce, you can consider it as a HelloWorld program using MapReduce in Hadoop, WordCount problem.
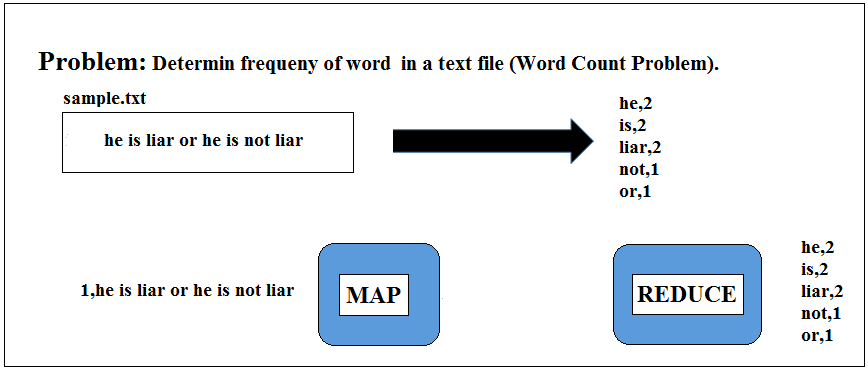
Figure 5: Reverse Engineering Process to Break Up the Problem in MapReduce Solution
The problem statement is we have to find the frequencies of each word in a given text file. You can assume this file as larger as you want with several billion of records but I have used a single record for the sake of understanding.
Here our job takes input as “he is liar or he is not liar” and it should produce output as words followed by the occurrence of the word in the file as given in the snapshot above. So the output should be he, 2, is, 2, liar, 2, not, 1, or, 1 as he, is, liar appeared twice and not and or appeared once in the file.
Here, our challenge is that how the Mapper break up the input record so the Reducer would be able to produce the output as shown.
Let’s see the algorithm to do that:
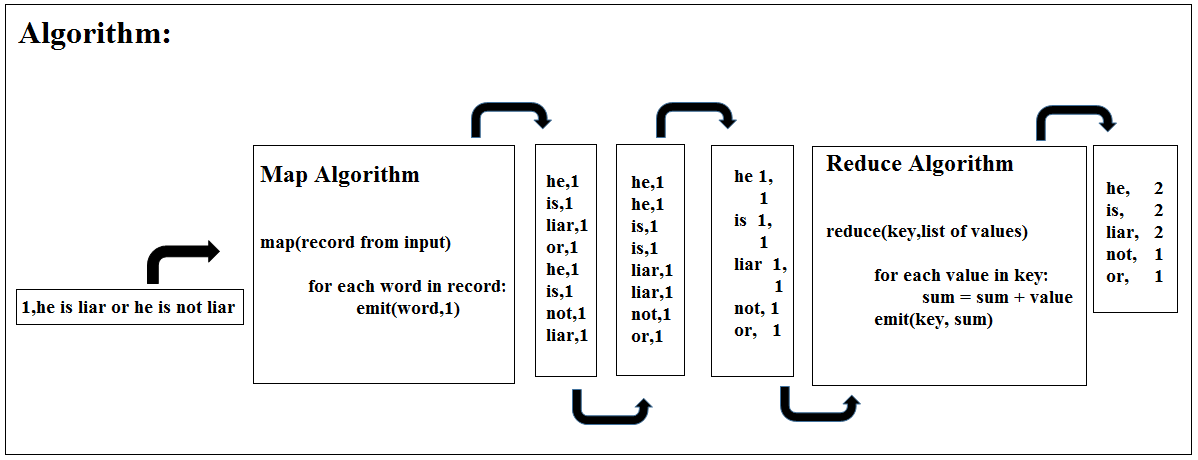
Figure 6: MapReduce Algorithm
Here map method would receive the input record as “1, he is liar or he is not liar” here 1 signifies the byte offset supplied by Hadoop. So the map side algorithm would tokenize the record into words and for every word it would emits < word, 1 > as < key, value > pairs. So the output would be:
< he, 1 >
< is, 1 >
< liar, 1 >
< or, 1 >
< he, 1 >
< is, 1 >
< not, 1 >
< liar, 1 >
you can signifies that the word has been encountered once and it should be sorted on the basis of Key, here in our case Keys are Words and Values are Frequencies. So the sorting is done by Hadoop and Key, Value pairs are get arranged in alphabetic order:
< he, 1 >
< he, 1 >
< is, 1 >
< is, 1 >
< liar, 1 >
< liar, 1 >
< not, 1 >
< or, 1 >
For Reducer to process Key, Value pairs would be changed to Key and List of values. So now it would look like:
< he [1, 1] >
< is [1, 1] >
< liar [1, 1] >
< not [1] >
< or [1] >
The Shuffle & Sort step provided by Hadoop put the Keys and their Values together. Now Reducer would call the reduce method once per key and in the method, it would iterate over the values of each key and sum it up to produce the result as Key, tap separated Value:
he, 2
is, 2
liar, 2
not, 1
or, 1
Word Count Application With Multiple Mapper and Reducers
Let’s see the execution of the above problem with two Mappers and two Reducers
Consider a case when two Maps are running a parallel and having input as “1, he is liar” and “15, he is not liar” respectively where 1 and 15 are the byte offset supplied by Hadoop. In the real world, there would be several Map processing several blocks (64 MB, 128 MB or 256 MB) of the original huge dataset.
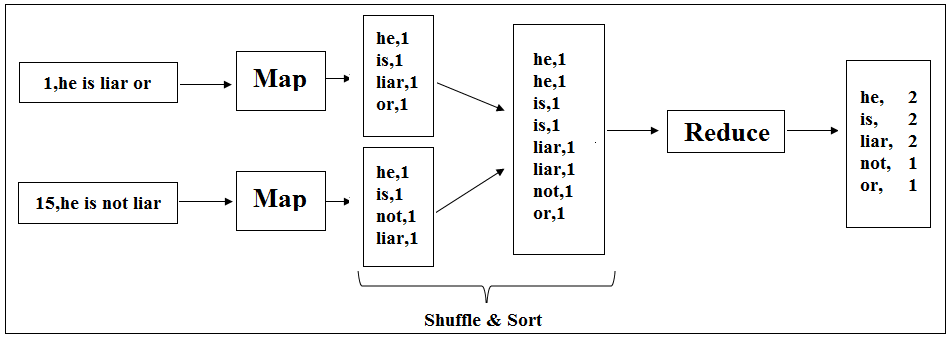
Figure 7: Word Count Application with Two Mappers
As we have already seen, the Mappers tokenize the input records into words and emits 1 as value. The Maps output would be Shuffled & Sorted by Hadoop. Again these outputs would be fed to Reducer and Reducer processes it to produce the final result. Here the power of parallelism has been used at Map phase.
The power of parallelism can be used to Reduce phase too. In this case, input to Reducer would be partitioned on the basis of two points:
- First, all the values for a particular key go to the same Reducer.
- Second, the key distribution amongst the Reducers should be almost equal.
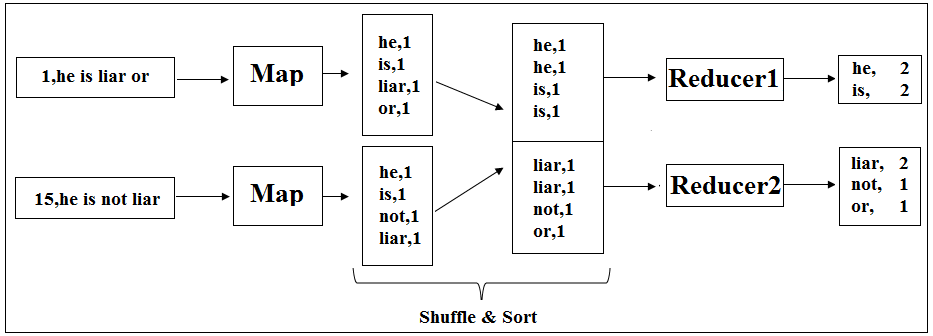
Figure 7: Word Count Application with Two Reducers
A single Reducer outputs a single sorted file while two Reducers output two individual sorted files. So the number of output files would be equal to the total number of Reducers used in the application. In the snapshot given above, you can notice that the words “he”, “is” and “liar” produced by two different Mappers but in the Reduce phase these are processed by the same Reducer to produce the result. This has been possible only because of the Shuffle & Sort phase in between which is very critical to any MapReduce solution. Here it is important to understand that the keys are processed in a distributed fashion at Map phase and in Reduce phase they brought together so that the processing of all the values to a particular key can be done by the same Reducer and all of these possible because of Shuffle & Sort phase.
So, if you have understood the concept of Reverse Engineering, you are able to break the problem to write the Map and Reduce algorithm and design the MapReduce solution. MapReduce code can be done in many programming languages but in this course, you will encounter the examples source code written in Java but you are free to implement them in your choice of language.